
This is a fun story, with a series of technologies and topics that I couldn’t believe they were capable of living together… EDM, TikTok, Text-To-Speech, AI, Playwright… Many times, when going down this over-engineered rabbit hole, I thought, “OK, I have to write about this thing.” And also, “What am I doing here with my time?”
📚 Some context
So, here are a few key things to be aware of:
- I write reviews for an electronic music (EDM) blog. It’s not too professional, just my thoughts on the music I listen to.
- I’m a total newbie to TikTok, and I don’t use it regularly.
- Being lazy by nature, I love automating tasks.
Everything began when Instagram encountered copyright issues with the Italian SIAE regarding music stickers. Consequently, Meta’s social media platform decided to temporarily remove the option of adding music to posts. This was a significant concern for my blog since we frequently used this feature, allowing readers to listen to the music while reading the article on our homepage. Additionally, Instagram heavily emphasizes videos, following the success of TikTok, resulting in a continuous decline in reach for our static posts.
That’s when the idea struck me: “we should transition to video reviews.”
Social media isn’t the primary focus of our blog, and I use it sparingly. Typically, I write the review, publish it on the website, and then share an image containing the content and link on social media using Hootsuite. I’ve automated the process as much as possible, so it usually takes no more than 5 minutes (excluding the time required to write the content, of course, but that’s a separate matter).
Therefore, editing and recording TikTok videos shouldn’t exceed that time frame; that was the main priority. I also wanted to acquire video editing skills that could prove useful for future projects. Additionally, since we’re on the topic, I thought it would be beneficial to explore the chaotic realm of TikTok, considering it’s the direction in which social media is evolving.
🏠 The starting point: RedditVideoMakerBot
My idea was to download generic abstract video backgrounds, add the sound of the reviewed song using Python and FFMPEG, and manually insert the article text with the TikTok app before uploading. It was a bit tedious and slow, but since this was an experiment for a social media platform I don’t use and a small niche blog, there was no pressure.
Then, I stumbled upon RedditVideoMakerBot, my Lord and Savior.
I want to publicly thank and praise elebumm and their team for this ingenious repository. It has 5k stars, 70+ contributors, advanced CI pipelines, and a list of libraries in the requirements with some famous names:
- playwright (web testing framework)
- praw (Reddit’s API wrapper)
- pytube (YouTube’s downloader)
- ffmpeg-python (video editing)
- Flask (micro-framework for web apps)
- pytorch, transformers (AI libraries)
- gTTS, pyttsx3 (Text-To-Speech models)
Are we building a spaceship?! No, this complex and DEFINITELY over-engineered architecture serves one, very, very specific purpose.
Scrapes a post’s data from Reddit and create a TikTok videos with an AI’s text-to-speech-generated voiceover and a gameplay background
This is ridiculously specific and I’m fascinated by the capabilities of programmers who are adding features to this amazing project. The level of configuration is impressive, with a GUI, multiple voice options, AI-powered post filtering, and even content translation. The settings are extensive and well-documented. This is better maintained than many core libraries in Python!
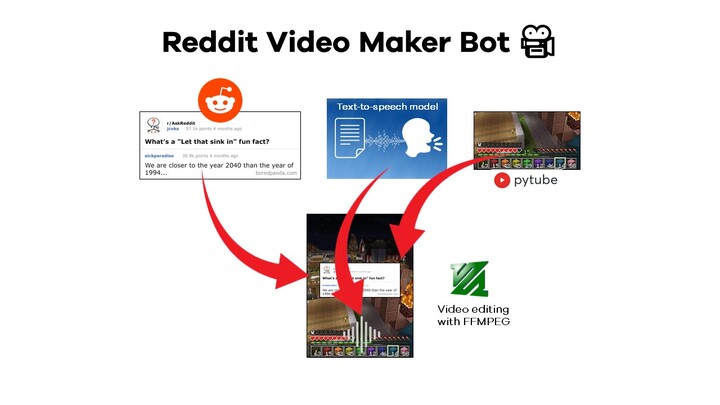

So I forked it and started building my OWN TikTok creator framework starting from RedditVideoMakerBot.
🕷️ Gather text and screenshots from my blog
The initial task was to obtain the content: innstead of relying on the Reddit API, I made some code adjustments and replaced it with an HTTP request to my public blog’s website. This enabled me to download the paragraphs and utilize headless Google Chrome with Playwright to capture screenshots for each segment of the video.
🎤 Generate the voiceover
RedditVideoMakerBot offers an extensive range of 7 libraries, including Streamlab and AWSPolly, along with over 20 voices for text-to-speech conversion. The advancements in this technology are truly remarkable, with some voices sounding incredibly human-like.
For my project, I opted for the “male funny” voice from TikTok, which is conveniently accessible with an account and has a natural tone that suits my needs perfectly. The code then combines multiple small .mp3 files, merging them into the first component of the final result sync.

🔍 Finding ‘The Drop’
The initial steps were relatively straightforward, but that’s when I had to take the reins. My task was to incorporate the song that is being review into the audio track as a background while the text-to-speech (TTS) voice narrates the article.
To achieve this, my code opens the song’s .mp3 file, crops it to match the duration of the voiceover audio, reduces its volume by 70%, and seamlessly blends the two files together. Luckily, FFMPEG, the library used for video editing, handles these tasks, saving me the need to learn another framework.
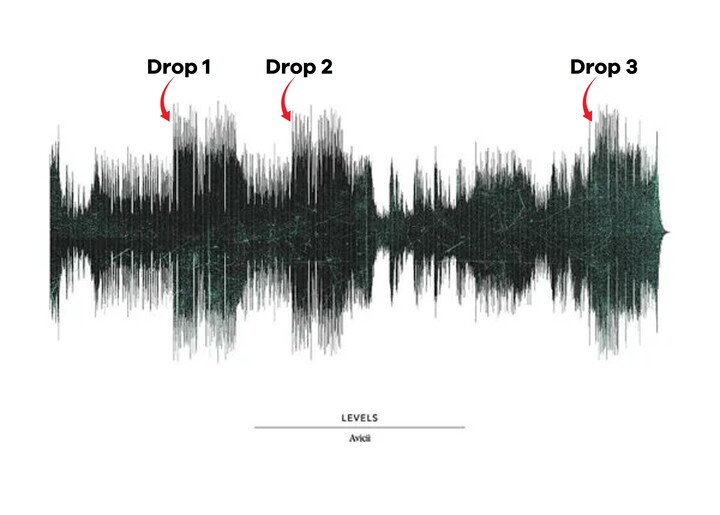
However, I encountered an obstacle at this point. I wanted the most energetic section of the song, known as the “Drop” or the climax, to start right at the beginning of the video to immediately capture the viewer’s attention. Automating this process turned out to be more challenging than expected. While it’s a simple task for a human, finding the right segment programmatically proved to be non-trivial.
During my research, I came across an intriguing thesis titled “Finding ‘The Drop’: Recognizing the climax in electronic music using classification models” by Koen van den Brink. The author utilized AI techniques, including Support Vector Machines and Convolutional Neural Networks, to identify the climax point in a song by analyzing its spectrogram. Discovering this thesis was a delightful moment as I realized someone else had faced a similar problem and even conducted research on it, providing valuable insights and motivation for my own project.

However, I opted not to train an entire convolutional neural network and over-engineer my solution solely for finding the right segment for my TikTok videos. Instead, I relied on my personal experience and examined a few spectrograms, measuring the noise levels (in decibels) at each second of the song. Surprisingly, this approach yielded satisfactory results without the need for complex AI models.
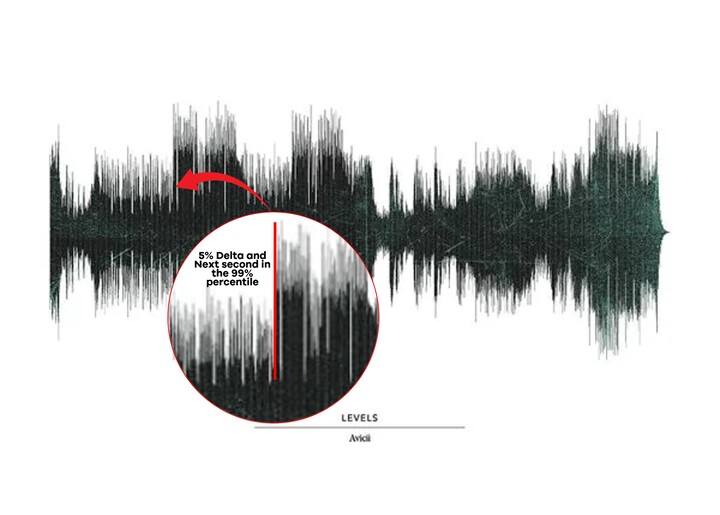
My function kicks in after 25% of the song has played and looks for a specific moment when:
- The next second is at least 5% noisier
- The noise level in the next second should be in the 99th percentile across the entire duration of the song
Yep, that’s the climax. So simple, so effective. It works for many music genres and took me 5 minutes to code.
def find_drop(df: pd.DataFrame) -> int:
THRESHOLD_MAX_DB = round(df.DB.max() * 0.99, 2)
THRESHOLD_DELTA = 0.05
for i in range(len(df)-1):
current_sec = df.iloc[i]
next_sec = df.iloc[i+1]
delta = (next_sec.DB - current_sec.DB) / current_sec.DB
if (next_sec.DB > THRESHOLD_MAX_DB) and (delta > THRESHOLD_DELTA):
print(f"Found a drop! At #{current_sec.name}")
return current_sec.name
✂️ Merge audio, screenshot and video parts
At this stage, working with FFMPEG drove me a little crazy. The Python wrapper posed significant limitations, as it is primarily designed as a command-line tool rather than a comprehensive library. I had to meticulously synchronize different elements: the segments of screenshots, the background video featuring EDM festival footage, and the combined voiceover with background music, while ensuring that the resolution was properly cropped for mobile devices, which added further time to the process. Throughout all of this, the persistent and unhelpful ffmpeg error messages continued to haunt me (until I discovered how to override the stderr)
🏆 The Result: my first TikTok!
The videos I can generate may not be award-winning or as captivating as the average TikTok content, but for me, it’s a personal victory. I take great pride in my tiny framework, which can be adjusted for other solutions in case of new video/audio editing ideas.
During this process, I gained valuable insights into the reliability of Text-To-Speech technologies, which have come a long way, and FFMPEG, a powerful tool for editing multimedia files once you grasp its commands. Previously, I perceived video and audio editing as daunting, requiring complex software and expertise (which it does, for professional purposes!). However, being able to make basic edits with code gave me a sense of accomplishment.
Currently, I have garnered a modest number of views (under the thousand) on TikTok. I need to explore ways to enhance performance and determine if this type of content can truly succeed on the platform. Additionally, I aspire to evolve the FFMPEG component, perhaps by incorporating transitions or more advanced visual effects.
One thing is certain, this has been an enjoyable experience, and I’m excited to continue exploring and refining my work. I extend my gratitude once again to Lewis Menelaws (elebumm) and his library for providing the foundation for this endeavor.