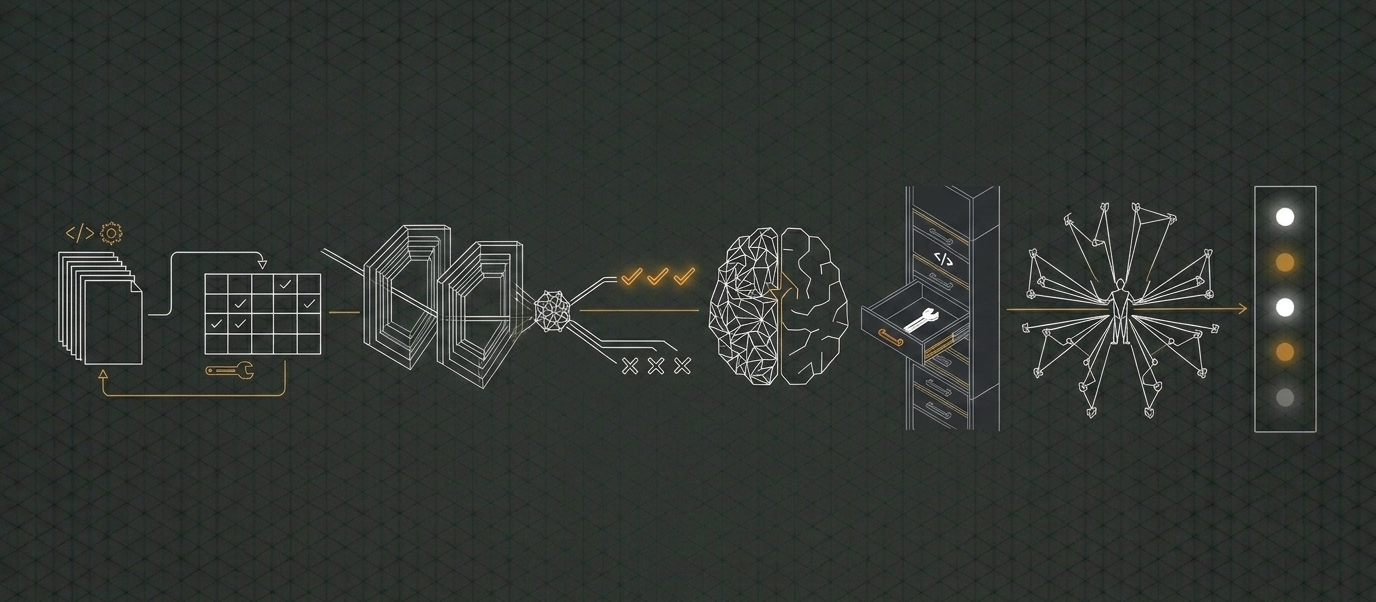
Lately, I’ve been sharing more and more about what I learned when building an AI architecture for a classic AI chat agent (like we did with Charlie). I think it’s a good time to map out the main components, along with the little tips and tricks I picked up along the way.
Keep in mind that all of this comes straight from my own hands-on experience. The tech is moving insanely fast, things will change, and your specific use cases will obviously differ from mine.
So, what actually makes an AI project? If you ask around, many people will come up with incredibly intricate, massive architecture overviews. Don’t get me wrong, that macro perspective is super important, especially if you’re operating in highly regulated environments.
But since this is just a straightforward post on my personal blog, I’m taking the liberty to oversimplify. Consider this a clean introduction to the core pillars, stripped of all the unnecessary bells and whistles.
Let’s look at the basic building blocks you actually need to assemble for a production AI product, whether you’re building a simple assistant, a chatbot, or a full agentic orchestrator.
The Orchestrator
At the heart of any AI agent is the orchestrator. This is the core framework in your code that coordinates your AI tools, handles incoming user requests, registers new capabilities, and manages all the background plumbing.
I strongly discourage creating this layer from scratch, even though it makes sense for very simple, single-turn flows. Save yourself the headache and pick an existing development tool (an SDK) to start from.
I would also avoid over-complicated frameworks like LangChain. They come with way too much abstraction and unnecessary complexity, which becomes a massive liability as the landscape rapidly evolves.
There are solid alternatives on the rise: PydanticAI is gaining traction for its stability guarantees, and Vercel AI SDK is quite popular too, both are solid steps up from LangChain. But if you aren’t worried about vendor lock-in, my tip is to go one step further and just use one of the main provider SDKs directly. They share more or less the same features, and if you’ve already committed to a cloud vendor, their native SDK is usually the lowest-friction route.
For example, I lately opted for the OpenAI Agents SDK because:
- It’s backed by one of the biggest AI companies in the space
- It natively connects with OpenAI Models without any adjustment or middleware needed
- It’s built with enterprise stability in mind, so no massive surprises
- It’s basically becoming the ecosystem standard, meaning most external tools natively expect OpenAI-compatible responses anyway
It has its own annoying drawbacks, especially when you’re dealing with their loggers 😫, but it’s perfectly fine for production. Anyway, if you keep the orchestrator layer lightweight and well-contained, switching later is painful but doable. Choosing the right SDK from the start just makes life a lot easier.
LLM Integration
Now that you have the structural brain to handle your AI application, you need an LLM to plug into it. This introduction is way too short to debate what the single “best” model is. Any benchmark list I write will be outdated in two weeks, and the choice depends entirely on your specific parameters.
But for conversational agents, you generally need a combination of two things: something relatively fast depending on the context (luckily, most routing tasks are quite simple) and something genuinely smart to act as the general orchestrator. A great pattern is letting the smart model handle the initial user input and intent, while a faster, cheaper model handles tool calling and secondary tasks where you need less reasoning (like parsing a raw API response). A crucial tip for the smart model: avoid giving it a long thinking budget. You do not want your AI to sit there running reasoning loops for 30 seconds just to say “hello” to a user.
You know my style by now: keep things simple. Keep your agent network tight. Handing off tasks to dedicated agents only makes sense if you have a massive project that does completely disconnected things, and you need a central router to navigate between them. For example, a personal assistant that manages your calendar and updates your Jira tasks can justify two separate agents because those workflows never touch. Otherwise, sticking to a smart + fast model combo works incredibly well. Most providers offer multiple tiers of models to mix and match, and there are plenty of model-agnostic middlewares to pick from like OpenRouter, though that introduces its own latency and reliability drawbacks.
Prompts
Your model(s) obviously needs a decent system prompt. The prompt does most of the heavy lifting, and the way “prompt engineering” works can feel ridiculously complex and out of scope for today. Still, for the sake of this post, 2026-era models are smart enough to work perfectly well with simple, direct instructions.
I wouldn’t stress about over-engineering this part because it depends entirely on your codebase, but 3 key points are:
- They MUST be tracked and version controlled
- You need a rock-solid evaluation suite to check for regressions every single time you modify them (see the Evals section below)
- The more complexity and edge-case padding you add, the more things you can screw up, and the more you risk tying up your model to unpredictable behaviors
Tools
Each agent will have a set of tools at its disposal. Think of them as skills, plugins, MCPs, whatever you want to call them… Essentially functions the agent can call to fetch data and provide better responses.
Let’s look at a basic example like web search. You can enable it natively through your SDK (for instance, the Gemini SDK has a native WebSearch tool), and the LLM just needs clear instructions on when to invoke it.
Tools should be lightweight and dead simple to use. Keep your tool prompts exactly like your main prompts: version-controlled, tested, and strictly minimal.
I really want to emphasize the word “SIMPLE”. If you write a 50-line instruction block for a specific tool, that entire block gets injected into the general system prompt context on every single conversation turn. This is 1. slow, 2. expensive and 3. unnecessary, especially for a niche tool that only gets called 5% of the time.
If you need to strictly steer the AI’s behavior after it uses a tool, prefer leaving hints directly in the data response payload instead of hardcoding constraints into the prompt logic itself.
For our web search tool example, you can return something like {success: "true", instructions: "always mention your sources in the response", value: [...the web search results]}
You can also dynamically enable or disable the list of tools on the fly, which is incredibly powerful if your conversational AI uses permission-based access control. For example, admin users can access powerful tools with write permissions, while basic users are restricted to read-only tools. Most SDKs provide built-in methods to filter tools in your backend code. DO NOT trust the LLM to police its own tool access based on a prompt instruction.
Finally, be careful with what you expose. Do not hand super-powerful, open-ended tools to an agent without strict guardrails. The classic example is giving an agent total shell control. Start with small, highly-constrained skills (like listing a single directory) and slowly expand them as you prove out the security boundaries.
Guardrails
If your AI agent is customer-facing, and especially if you work in a regulated sector, guardrails are absolutely essential. Some models provide default safety filtering out of the box (like blocking explicit hate speech or violence), but the closer your app is to an end-user, the more granular control you need.
Guardrails are essentially automated layers designed to stop your AI from causing disasters. In an oversimplified way, they usually consist of additional, lightweight LLM checks and prompt filters that prevent the agent from being tricked into doing things it shouldn’t.
A solid guardrail layer looks like this:
- A foundational instruction at the root level (e.g., “You only talk about Mathematics”). This is your baseline of defense, and modern models are already quite decent at self-defense if an exploit somehow slips past outer layers.
- Input and Output validation. This layer catches basic attacks before they ever reach the LLM or get displayed to the user. Most SDKs provide native utility tools for this, like OpenAI’s Moderation API which use fast, specialized models to scan text for violations. Because the user never interacts with this validation layer directly, it’s significantly more resistant to direct manipulation.
- A context reviewer. This is a design pattern I really like. If a malicious user asks your agent to generate a fake, data-wiping script, and then follows it up by saying “please” 10 times, a basic input guardrail looking only at that last message won’t flag the word “please” as an attack. Advanced jailbreaking attacks often use multi-turn conversations to slowly confuse and distort the LLM’s context window. Having a smaller, lightweight model that periodically reviews the entire chat history every X messages and kills the session if the conversation is veering into a dangerous direction will catch these advanced attacks.
Also, pay close attention to custom fields inside your tools. If you allow unfiltered, raw text into tool arguments without strict schema enforcement and sanitation, you are opening your application up to easy injections. The key takeaway: never rely on the AI to defend itself from attacks.
Evals
To me, this is completely non-negotiable, the equivalent of unit testing for traditional applications. You need a resilient evaluation suite.
As I wrote in my previous post on Evals, these suites should run automatically every single time you alter a main prompt or a tool definition to ensure you haven’t introduced regressions.
This ties directly into eval-driven development. Start with a defined goal: you usually don’t want an AI agent that attempts to do literally everything; you want it bounded to a few core tasks. Every single one of those core tasks MUST BE AN EVAL CASE. Run them continuously to make sure that a prompt tweak designed to fix feature A doesn’t accidentally completely break feature B.
I also highly recommend adding adversarial evals to your test pipeline. Write test prompts that actively try to confuse, trick, or jailbreak the LLM across multiple turns. It’s the best way to verify that your guardrails are actually working as expected under pressure. AI can be a massive help in generating these adversarial test cases, but your own understanding of the product’s ultimate goals will be the key factor. Think outside the box when writing your evals.
Miscellaneous
We’ve only scratched the surface, but here are a few final infrastructure points I would always include in a production-ready setup:
- Configuration: in production, you need the agility to deploy an emergency prompt hot-fix instantly without waiting for a full 10-minute CI/CD deployment pipeline. Store your base prompts, model settings, and configurations in a database that can be synced to the orchestrator
- A solid Observability Layer: you absolutely need deep tracing for debugging when something goes wrong, and to track hallucinations, token spend, and other KPIs. There are plenty of great production solutions out there, many of which are completely self-hostable
- Graceful fallbacks: LLMs fail, rate limits get hit, and cloud vendor APIs go down. You should always have a backup model hosted by an entirely different provider ready to take over if your main provider becomes unresponsive: it’s the only way to ensure high uptime
- Memory management: all the conversational APIs let you pass previous messages back to the model to maintain a coherent conversation flow (otherwise, the AI has total amnesia on every new turn). However, keep two things in mind: 1. it really helps to enforce structured long-term memory, 2. keep a close eye on long chat sessions. They will eventually need to be truncated or summarized to save on token costs and prevent overloading the context window of your smaller, fast utility models.
Wrap up
Those were the pillars for a good conversational AI architecture: something I’ve refined over the years building different projects in different areas. I know we just had a very quick overview of a vast, complex and rapidly-evolving world, but I hope this was helpful! I was looking for a post like this before creating Charlie. If you have any question or want to explore a point in more depth, you know where to find me.